
MySQL vs PostgreSQL Comparison: Which One to Choose?
Default
-
By Hardik Savani . April 07, 2026
Default
By Hardik Savani . April 07, 2026
Choosing the right database is one of the most critical architectural decisions you will make when building an application. This choice fundamentally influences performance, scalability, data integrity, and the types of features you can realistically implement. At the heart of most applications lies a Relational Database Management System (RDBMS), a technology that has proven its resilience and utility for decades by organizing data into structured tables with predefined relationships. Within the world of open-source RDBMS, two names consistently dominate the conversation: MySQL and PostgreSQL. Both are powerful, mature, and backed by vibrant communities, yet they are built on different philosophies that make them better suited for different tasks. Making an informed decision requires looking beyond surface-level popularity and delving into their core architecture, feature sets, and ideal use cases. MySQL, currently managed by Oracle, has long been the default choice for web development, celebrated for its speed and simplicity. PostgreSQL, a community-driven project, is renowned for its feature-richness, extensibility, and strict adherence to SQL standards. The decision isn't about which one is universally superior, but which one aligns perfectly with your project's specific needs. According to the widely respected DB-Engines ranking, as of early 2024, MySQL remains one of the top two most popular databases worldwide, while PostgreSQL sits firmly in fourth place and has consistently won the "DBMS of the Year" award more than any other system, showcasing its rapidly growing adoption and developer loyalty. This ongoing contest for market and mindshare underscores the importance of a detailed comparison to guide your strategic technology choices.
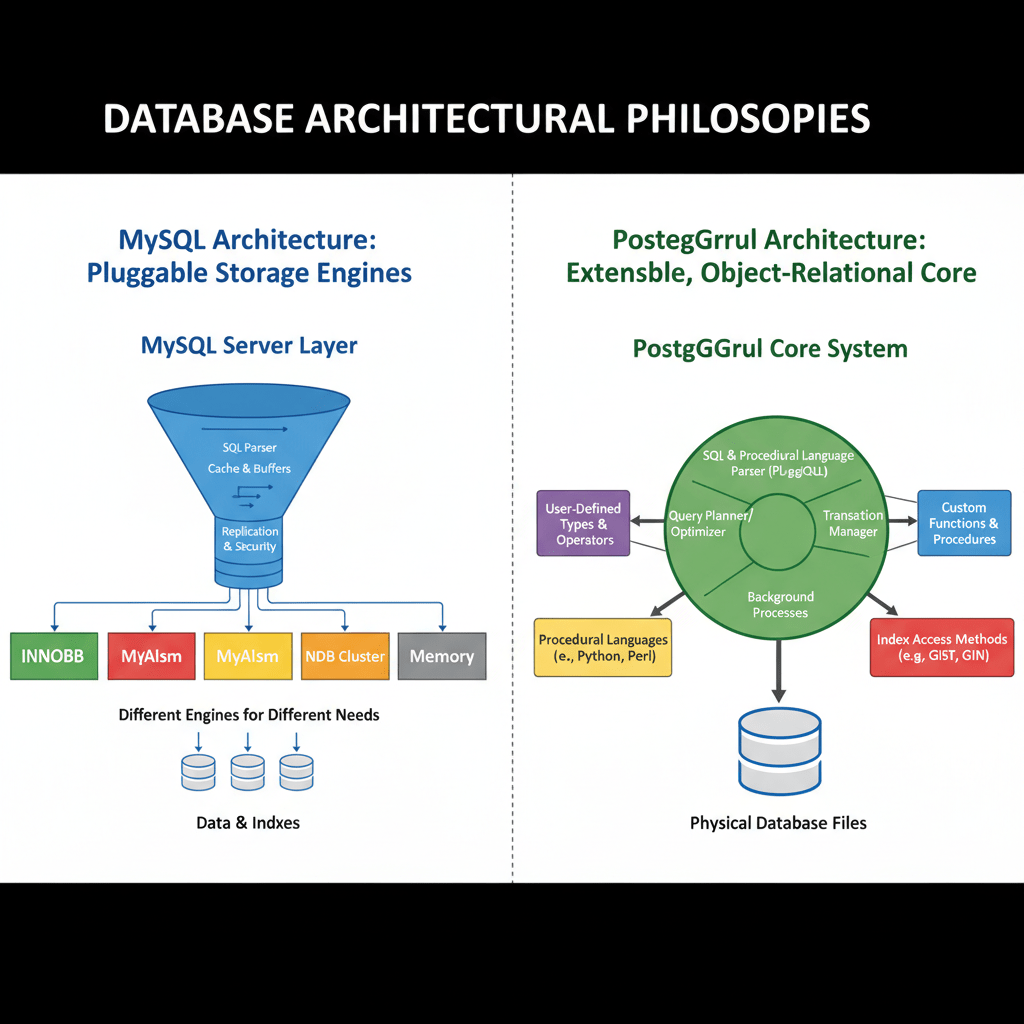
MySQL's design philosophy has always been centered on being fast, reliable, and easy to use. This focus made it the cornerstone of the original LAMP stack (Linux, Apache, MySQL, PHP), which powered a significant portion of the early web. Its architecture is notably modular, featuring a pluggable storage engine system. This allows users to choose the underlying engine that best fits their workload. The default and most common engine is InnoDB, which is fully ACID compliant (Atomicity, Consistency, Isolation, Durability) and supports row-level locking, foreign keys, and transactions, making it suitable for a wide range of general-purpose applications. In the past, the MyISAM engine was popular for its exceptional speed in read-heavy scenarios, like content management systems or catalogs, though it sacrificed transactional integrity and crash safety. While InnoDB is now the standard for virtually all use cases, the existence of this architecture highlights MySQL's emphasis on providing tailored performance. The system excels at handling high volumes of read operations, which is a common pattern for websites and many online services. Its setup process is straightforward, and a vast ecosystem of tools, hosting providers, and community knowledge makes it incredibly accessible for developers of all skill levels. For a foundational understanding of its practical application, reviewing a MySQL Example can provide valuable context. The primary takeaway is that MySQL prioritizes operational speed and ease of management over a sprawling feature set, making it an incredibly effective tool for applications where these attributes are paramount.
PostgreSQL, often affectionately called "Postgres," operates under a different guiding principle: to be the world's most advanced open-source relational database. Its core philosophy emphasizes extensibility, data integrity, and strict standards compliance. Unlike MySQL's focus on a handful of specialized use cases, PostgreSQL aims to be a robust, all-in-one solution capable of handling a vast array of complex data workloads. It is not just a relational database but an object-relational database management system (ORDBMS). This means it supports not only traditional data types but also custom types, structured types (like rows or composites), and a variety of advanced object-oriented features. PostgreSQL’s implementation of Multi-Version Concurrency Control (MVCC) is often cited as being more robust for environments with high volumes of concurrent read and write operations, as it minimizes lock contention. This architectural choice makes it exceptionally well-suited for complex transactional systems and data warehousing. Furthermore, its commitment to the SQL standard is legendary; it often implements new standard features before other databases. But its true power lies in its extensibility. Developers can create custom functions, data types, operators, and even index methods. This has fostered a rich ecosystem of powerful extensions, with PostGIS for advanced geospatial data analysis being the most famous example. The system is designed for developers who require deep control, rich data types, and the ability to execute complex, analytical queries directly within the database, ensuring that data integrity and correctness are never compromised.
One of the most significant differentiators between the two databases is the breadth and depth of their supported data types. While both systems cover all the standard numeric, string, and temporal types, PostgreSQL offers a far richer and more specialized native toolkit. It includes advanced types such as arrays (allowing you to store a list of values in a single field), hstore for key-value pairs, network address types like inet and MACADDR, a native UUID type, and geometric types for computational geometry. This built-in support can drastically simplify application logic by offloading complex data validation and manipulation to the database itself. MySQL, while having expanded its offerings, has historically been more conservative. For instance, while it now has a JSON data type, PostgreSQL's JSONB (binary JSON) is often considered superior due to its efficiency and advanced indexing capabilities. PostgreSQL is also notoriously stricter with data validation. It enforces strong typing and constraints rigorously, which minimizes the risk of storing invalid data. This commitment to data integrity is a cornerstone of its design and a primary reason it's favored for financial, scientific, and analytical applications where data correctness is paramount.
| Feature/Data Type | PostgreSQL Support | MySQL Support | Notes |
|---|---|---|---|
| Arrays | Native, multi-dimensional | No (requires workarounds) | PostgreSQL allows storing arrays of values in a single column. |
| JSON | JSON & JSONB (binary, indexed) |
JSON (text-based) |
PostgreSQL's JSONB is generally faster for queries and supports GIN indexing. |
| Geospatial | Excellent (via PostGIS extension) | Basic (native spatial types) | PostGIS is the de facto industry standard for serious GIS work. |
| Network Addresses | inet, cidr, macaddr |
No (stored as strings/integers) | Simplifies network-related application development. |
| Custom Types | Yes, via CREATE TYPE |
Limited (via ENUM, SET) |
PostgreSQL's extensibility allows for creating complex, user-defined types. |
The performance debate between MySQL and PostgreSQL is nuanced and has evolved significantly over time. Historically, MySQL held a clear advantage in read-heavy workloads with simple queries, making it the go-to for blogs, directories, and many e-commerce storefronts. Its MyISAM engine was built for blazing-fast reads, and even with the transactional InnoDB engine, its architecture was optimized for high-throughput, low-complexity operations. PostgreSQL, conversely, has always shone in handling complex queries, large datasets, and high-concurrency environments with mixed read-write loads. Its query planner is widely considered more sophisticated, capable of optimizing intricate joins, subqueries, and window functions more effectively. Its MVCC implementation allows for greater concurrency by providing each transaction with a "snapshot" of the database, reducing the need for explicit read locks and thus preventing readers from blocking writers and vice versa. However, this gap has narrowed. Modern versions of MySQL (8.0 and later) have introduced significant performance enhancers, including window functions, common table expressions (CTEs), and a much-improved query optimizer. InnoDB is now highly performant for a wide range of workloads. The general consensus today is that for simple web application workloads, the performance difference is often negligible. The choice should be based on the nature of the data and queries. If your application relies on running complex analytical queries or will experience heavy concurrent write activity, PostgreSQL often maintains an edge. If your primary need is high-velocity reads of simple data, MySQL remains an exceptionally strong contender. For a broader view, consider this video on database design principles.
PostgreSQL is renowned for its strict adherence to the SQL standard. It diligently implements features as specified by the official SQL definitions, which makes it predictable and reliable for developers who value standards-based development. This compliance extends to advanced features like window functions, CTEs, and robust transactional controls. MySQL, while largely compliant, has some idiosyncratic behaviors and non-standard extensions. Though recent versions have made great strides in closing this gap, developers moving between systems may encounter minor syntactical differences. To see a variety of standard database operations, browsing an SQL Example library can be very helpful. However, the most profound difference in this category is extensibility. PostgreSQL was designed from the ground up to be extensible. Users can add new functions, operators, data types, and index methods. This has led to a powerful ecosystem of extensions that add specialized capabilities directly to the database engine. The most famous is PostGIS, which transforms PostgreSQL into a feature-rich geographic information system. Other examples include TimescaleDB for time-series data and Citus for distributed databases. MySQL's extensibility is primarily focused on its storage engine architecture and plugins, which is powerful but generally less focused on extending the SQL language itself. For developers who foresee the need for specialized data processing or want to build a feature-rich application on a flexible foundation, PostgreSQL’s extensibility is a decisive advantage.
Both databases offer mature and robust solutions for replication, which is essential for achieving high availability, read scaling, and disaster recovery. MySQL has a long-established, easy-to-configure primary-replica (master-slave) replication system. It's straightforward to set up read replicas to offload read traffic from the primary server. For more advanced high-availability needs, MySQL offers semi-synchronous replication and, more recently, solutions like InnoDB Cluster and Group Replication, which provide a multi-primary, fault-tolerant architecture. PostgreSQL provides powerful built-in streaming replication, which can be configured as either asynchronous or synchronous. Logical replication was introduced in version 10, allowing for more granular control over which data changes are replicated, even between different major versions of PostgreSQL. While the built-in tools are powerful, the PostgreSQL ecosystem relies heavily on a suite of excellent third-party tools like Patroni, Stolon, or pgpool-II to manage automated failover and connection pooling, offering immense flexibility but sometimes requiring more complex configuration. Both systems can scale to handle massive workloads, but their approaches reflect their core philosophies. MySQL’s simplicity makes setting up a basic read-scaling architecture very accessible. PostgreSQL provides the primitives for building incredibly robust and flexible replication topologies, often with the help of external tooling. This flexibility is particularly useful when considering advanced architectures, such as when you need to How to use multiple database in Laravel 12.
| Replication Feature | PostgreSQL | MySQL |
|---|---|---|
| Primary Method | Streaming Replication (Physical/Logical) | Statement/Row-based Replication |
| Synchronous Support | Yes, built-in | Yes (Semi-synchronous) |
| Multi-Master | Via 3rd-party extensions (e.g., BDR) | Yes (Group Replication/InnoDB Cluster) |
| Failover Management | Typically via 3rd-party tools (e.g., Patroni) | Integrated solutions (InnoDB Cluster) |
In the age of APIs and semi-structured data, robust support for JSON has become a critical database feature. Both MySQL and PostgreSQL offer native JSON data types, but their implementations and capabilities differ. MySQL introduced a native JSON data type in version 5.7. It stores JSON in an optimized binary format and provides a suite of functions for creating, manipulating, and searching JSON documents. Indexing JSON fields was initially limited but has improved in version 8.0 with support for multi-valued indexes. PostgreSQL provides two JSON types: json and jsonb. The json type stores an exact, text-based copy of the input, while jsonb stores the data in a decomposed binary format. This jsonb type is the real game-changer. It is slightly slower on insert due to the conversion process, but it is significantly faster to query. Crucially, jsonb supports Generalized Inverted Indexes (GIN), which allows for efficient indexing of every key and value within the JSON document. This makes querying nested or complex JSON structures incredibly performant. The extensive set of operators PostgreSQL provides for jsonb allows developers to treat a relational database almost like a NoSQL document store when needed, offering the best of both worlds. While MySQL's JSON support is more than adequate for many use cases, PostgreSQL's jsonb implementation is generally considered the gold standard for applications that heavily rely on querying and manipulating semi-structured data.
The choice of a database extends beyond its technical features to its surrounding ecosystem. MySQL boasts one of the largest and most established communities in the software world. Its long history as the default database for web applications means there is an immense volume of tutorials, blog posts, forum discussions, and third-party tools available. It is the "M" in the ubiquitous LAMP and LEMP stacks, and platforms like WordPress, Drupal, and Joomla are built on it. This widespread adoption means that finding developers with MySQL experience or managed hosting solutions is exceptionally easy. Being backed by a major corporation like Oracle also means there is clear commercial support and a predictable release cycle. The MySQL Official Documentation is extensive and well-maintained. On the other hand, PostgreSQL's community is known for being fiercely loyal, highly technical, and developer-centric. It is a truly open-source project, guided by a global development group, free from the control of a single corporation. This fosters a culture of innovation and a focus on solving complex technical challenges. Its community resources, including the excellent PostgreSQL Official Documentation, are top-notch. PostgreSQL is often the preferred choice in startups and enterprises that value technical sophistication and flexibility. The availability of managed services on all major cloud providers (Amazon RDS, Google Cloud SQL, Azure Database) has made both databases equally accessible from an infrastructure standpoint, leveling the playing field and allowing the decision to be based more on features and project fit than on operational overhead.
MySQL remains an outstanding choice for a wide range of applications, particularly where speed, simplicity, and a mature ecosystem are the top priorities. It excels in environments characterized by high-volume read operations. A classic use case is a Content Management System (CMS) like WordPress or a high-traffic blog, where the vast majority of database interactions involve fetching articles and pages. E-commerce platforms also frequently rely on MySQL for its speed in displaying product catalogs and handling a large number of user sessions, while its reliable InnoDB engine handles the transactional aspects of checkout. For online analytical processing (OLAP) applications that do not require extremely complex queries, MySQL can be a performant and cost-effective solution. Perhaps most importantly, it is an excellent choice when you need to get a project up and running quickly. Its straightforward setup, massive knowledge base, and the wide availability of skilled developers can significantly reduce development time and complexity. If your team has deep experience with MySQL or your application fits the classic web application mold, it is a proven, reliable, and powerful choice that is hard to go wrong with.
PostgreSQL is the definitive choice when your application demands data integrity, complex queries, and extensibility. For any system involving financial transactions, scientific data, or manufacturing logistics, its strict ACID compliance and robust data validation rules provide an essential layer of safety. Its advanced query planner and rich set of functions make it the superior option for data warehousing and business intelligence applications that require running complex analytical queries with multiple joins, aggregations, and window functions directly against large datasets. The single most compelling use case is for geospatial data services. With the PostGIS extension, PostgreSQL becomes a world-class Geographic Information System (GIS) that outperforms most specialized commercial alternatives. Furthermore, if you are building an application where you anticipate future needs for custom data types or non-standard data processing, PostgreSQL's unparalleled extensibility provides a future-proof platform. It allows you to build complex logic directly into the database, which can simplify your application code and improve performance. Choose PostgreSQL when your data is complex, your queries are demanding, and you need a database that can grow and adapt to sophisticated future requirements.
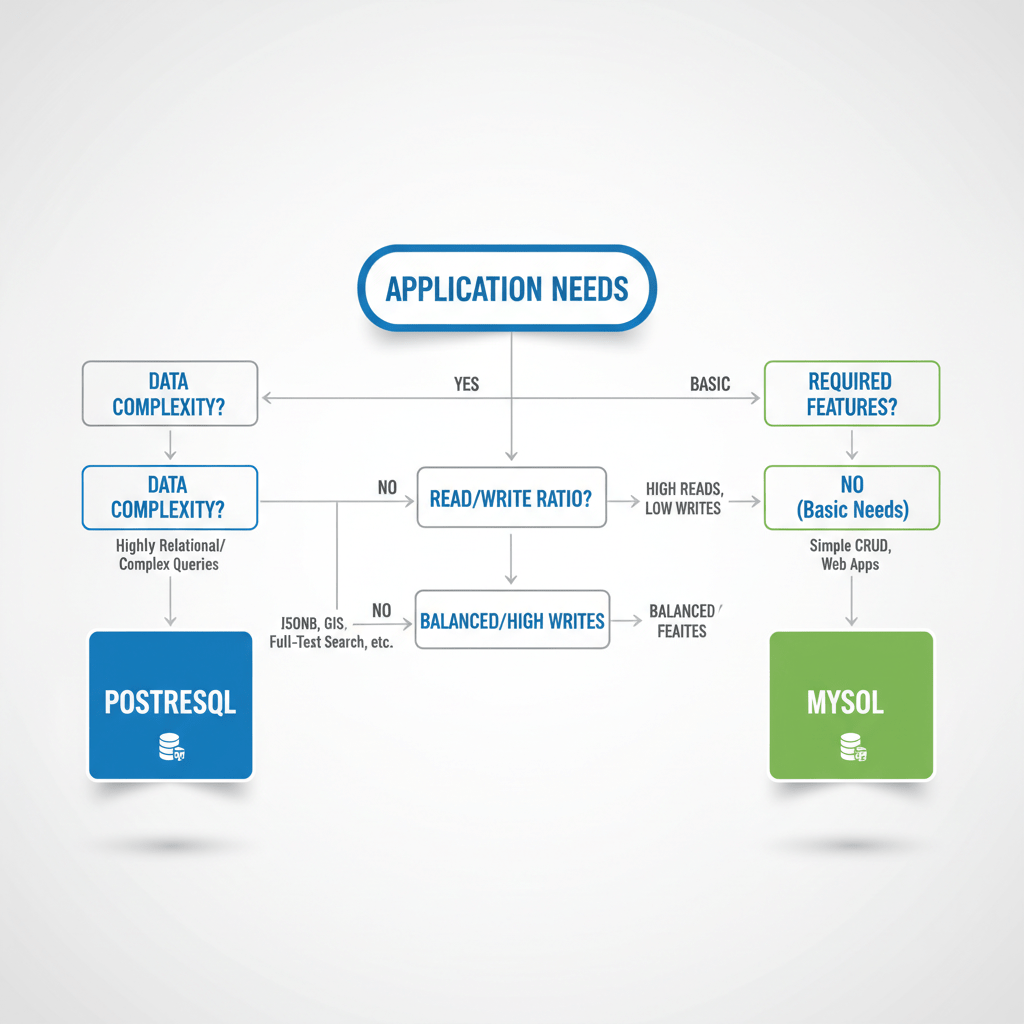
It is crucial to recognize that both MySQL and PostgreSQL are dynamic, actively developed projects. The lines of differentiation, while still clear in their core philosophies, are becoming blurrier with each new release. MySQL 8 introduced a host of features like CTEs and window functions that were once exclusive PostgreSQL territory. Similarly, PostgreSQL has made significant strides in improving performance for simpler workloads and enhancing its replication and high-availability toolsets. The modern developer is in an enviable position, with two exceptional open-source databases to choose from, each capable of handling demanding, mission-critical workloads. The decision should not be framed as a simple "MySQL vs. PostgreSQL" battle, but as a careful evaluation of your specific project needs. Consider your data's complexity, your expected query patterns, the scalability requirements, and the existing expertise of your team. MySQL offers a path of speed, simplicity, and widespread familiarity. PostgreSQL provides a road of power, flexibility, and uncompromising data integrity. By aligning the database's core strengths with your application's primary goals, you can build a robust and scalable data foundation that will serve you well for years to come.
TABLE OF CONTENTS


